Google Launches Gemini 3.1 Flash-Lite - Built for Intelligence at Scale

A deep dive into today's release of Gemini 3.1 Flash-Lite, Google's new model optimized for low-latency, high-volume, and cost-sensitive LLM traffic.
Disclaimers:
- At the time of this writing, I am employed by Google Cloud. However the thoughts expressed here are my own and do not represent my employer.
- The code provided here is sample code for educational purposes only. Please write your own production code.
Introduction
The AI landscape is moving at a breakneck pace, and today, Google took another massive step forward with the launch of Gemini 3.1 Flash-Lite. While much of the industry's focus over the last year has been squarely fixated on massive frontier models, Gemini 3.1 Flash-Lite represents a strategic pivot toward incredible efficiency and speed for developers and enterprises.
In a world where developers are increasingly looking to deploy AI across massive user bases with high-frequency interactions, having a model that is both highly capable and computationally inexpensive is a hard requirement.
What is Gemini 3.1 Flash-Lite?
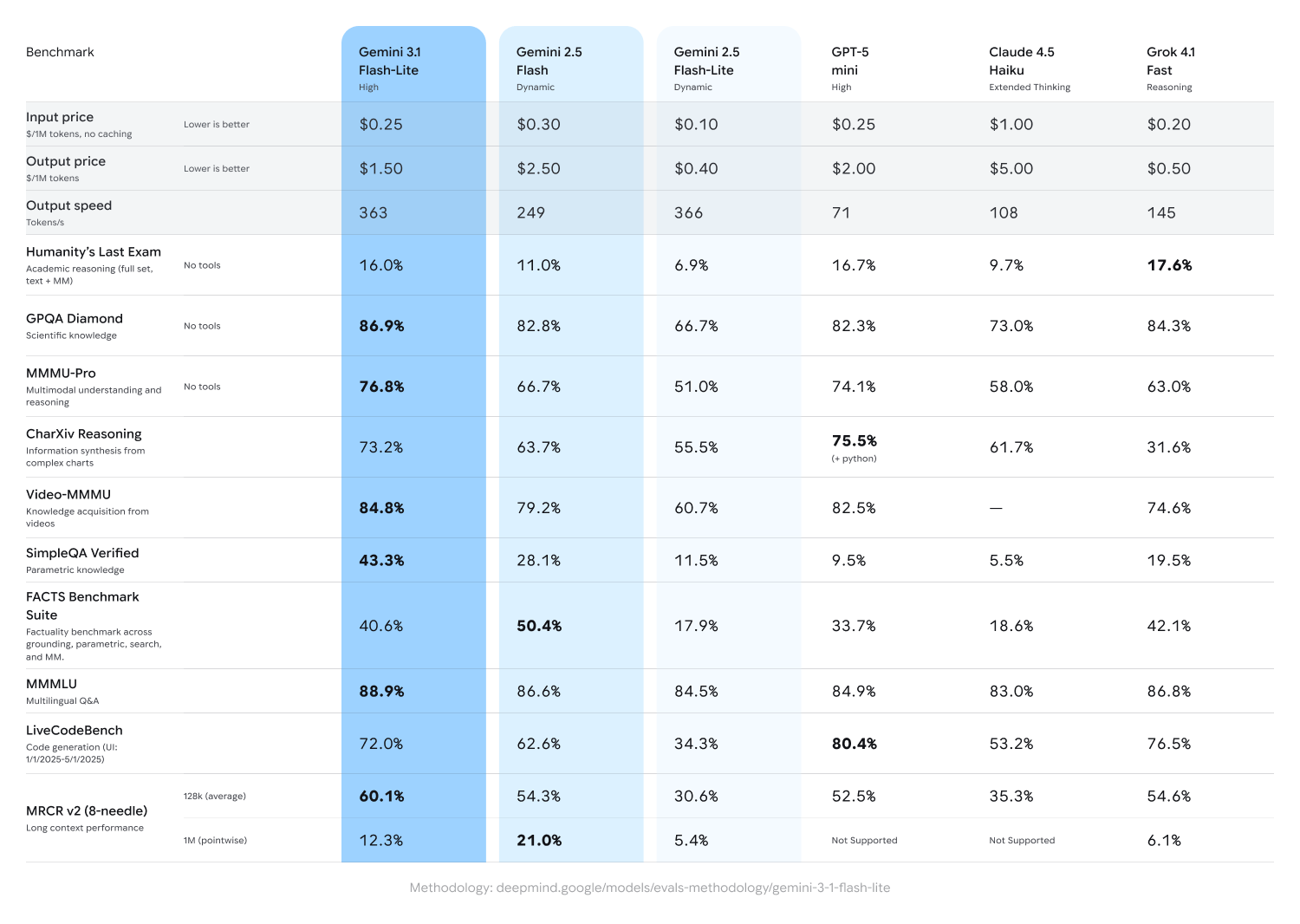
Gemini 3.1 Flash-Lite is the newest and most cost-efficient member of the Gemini 3.1 family. Designed specifically for low-latency tasks and high-volume environments, it inherits the advanced reasoning and multimodal capabilities of the Gemini architecture, but packages them into a highly optimized footprint that actually matches the performance of the older Gemini 2.5 Flash.
Here are a few key takeaways from today's announcement:
1. Cost-Efficiency & Speed at Scale
The most significant aspect of 3.1 Flash-Lite is its pricing and speed. It is priced at just $0.25 per 1 million input tokens and $1.50 per 1 million output tokens. It is demonstrably faster and more cost-efficient than 2.5 Flash, opening the door for developers to build applications like high-volume chatbots, real-time translation services, and automated content moderation without breaking the bank.
2. Massive 1M Context Window & Multimodality
Despite being a "Lite" model, it boasts an impressive context window that punches well above its weight class. It supports up to 1,048,576 input tokens, easily handling large document summarization, extended chat histories, and complex RAG (Retrieval-Augmented Generation) workloads.
Furthermore, it is fully multimodal, accepting text, code, images, audio, video, and PDFs as input. In fact, today's release notes specifically highlight improved audio input quality, making it exceptional for tasks like Automated Speech Recognition (ASR).
🔍 View Capability Upgrades
Gemini 3.1 Flash-Lite brings several major improvements over previous "Lite" generations:
- Matches 2.5 Flash Performance: Delivers the quality of the previous mid-tier model at a fraction of the cost.
- Expanded Thinking Support: Allows developers to control the model's reasoning depth (minimal, low, medium, high) to perfectly balance response quality and latency.
- Improved Instruction Following: Provides a highly reliable migration path for complex, instruction-heavy workflows.
3. Enterprise & Developer Ready
Gemini 3.1 Flash-Lite is available today in preview for developers via the Gemini API in Google AI Studio, and for enterprises via Vertex AI.
It supports the full suite of enterprise tooling, including Grounding with Google Search, Code execution, System instructions, Function calling, Structured output, and both Implicit and Explicit context caching.
Here is a quick example of how you can invoke the new model natively using the official Google GenAI SDK initialized for Vertex AI:
import os
from google import genai
from google.genai import types
# Initialize the client for Vertex AI
# Ensure you have authenticated via 'gcloud auth application-default login'
client = genai.Client(
vertexai=True,
project=os.environ.get("GOOGLE_CLOUD_PROJECT"),
location="global"
)
# Define the new Flash-Lite model endpoint
MODEL_ID = "gemini-3.1-flash-lite-preview"
# Generate content with specific configuration
response = client.models.generate_content(
model=MODEL_ID,
contents="Summarize the primary benefits of an event-driven architecture.",
config=types.GenerateContentConfig(
temperature=0.2,
max_output_tokens=500
)
)
print(response.text)
Why Efficiency Matters Now More Than Ever
We are reaching an inflection point in Generative AI. The initial novelty of massive, cloud-based models has settled, and the industry is now focused on unit economics and practical deployment at scale.
Running a massive flagship model for every single user interaction is financially unviable for most consumer-facing applications. By providing a highly capable "Flash-Lite" model, Google is giving developers the tools they need to build sustainable, scalable AI businesses.
You can use a tiered routing approach: hit Gemini 3.1 Flash-Lite for 90% of standard user queries and basic tool routing, and only escalate to larger models when deep, complex reasoning is absolutely required.
Looking Ahead
With the deprecation of older preview models coming up, and the Google Cloud AI Live+Labs events kicking off soon, it is clear that the 3.1 architecture is setting a new standard for performance per dollar.
I'm incredibly excited to see what the community builds with Gemini 3.1 Flash-Lite. The era of "AI everywhere" relies on these faster, more economical models, and today's release proves that extreme efficiency doesn't have to mean sacrificing capability.